Implementing Simple HashTable
Hash table is a very important and interesting structure. If I were you, I would love to have my own hash table implemented. So let’s get started with the most simple implementation. The following graph might help:
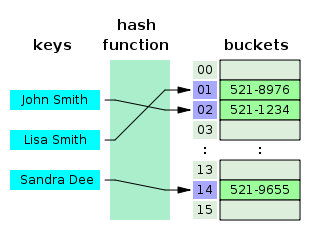
As everyone already knows, hash table contains (key, value) pairs. For example, when you take “John Smith” as key of hash table, there will be a hash function to transform the String type key value to a Integer as index. With the index, you could easily get the value. In this case, the (key, value) pair will be called as entry of hash table.
Now you are ready to implement it. Straight forward huh. Let’s get to the simplest part.
The code for hash table entry is:
public class HashEntry {
private String key;
private int value;
HashEntry(String key, int value) {
this.key = key;
this.value = value;
}
public String getKey() {
return key;
}
public int getValue() {
return value;
}
}
The code for hash table is:
public class SimpleHashTable {
private int TABLE_SIZE;
private int size;
private HashEntry[] table;
/* Constructor */
public SimpleHashTable(int ts) {
size = 0;
TABLE_SIZE = ts;
table = new HashEntry[TABLE_SIZE];
for (int i = 0; i < TABLE_SIZE; i++)
table[i] = null;
}
/* Function to get number of key-value pairs */
public int getSize() {
return size;
}
/* Function to clear hash table */
public void clean() {
for (int i = 0; i < TABLE_SIZE; i++)
table[i] = null;
size = 0;
}
/* function to retrieve value from the table according to key */
public int get(String key) {
int index = findIndex(key);
return table[index] == null ? -1 : table[index].getValue();
}
/* function to add value to the table */
public void put(String key, int value) {
table[findIndex(key)] = new HashEntry(key, value);
size++;
}
/* function to remove value to the table */
public void remove(String key) {
table[findIndex(key)] = null;
size--;
}
/* value to create the Hash code from he name entered */
private int calculateHashCode(String key) {
int mod = key.hashCode() % TABLE_SIZE;
return mod < 0 ? mod + TABLE_SIZE : mod;
}
private int findIndex(String key) {
int index = calculateHashCode(key);
while (table[index] != null && !table[index].getKey().equals(key)) {
index = (index + 1) % TABLE_SIZE;
}
return index;
}
}
I guess I don’t have to explain everything, just the core, findIndex() and calculateHashCode().
Explanation On Important Functions
The responsibility of function calculateHashCode() is to transform the String type key value to a Integer as index. Java has a function String.hashCode() to similar things, we could exploit that.
Take s = key.toCharArray(), Then s.hashCode() = s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1].
Now we have a 1 to 1 map from String to Integer, the only thing to do is to transform the integer to index of hash table. We can do this by modulo:
int mod = key.hashCode() % TABLE_SIZE; return mod < 0 ? mod + TABLE_SIZE : mod;
But what if we got collisions on index of hash table? For example:
key1.hashCode() = 4; key2.hashCode() = 8; TABLE_SIZE = 4;
Then we will need function findIndex():
int index = calculateHashCode(key);
while (table[index] != null && !table[index].getKey().equals(key)) {
index = (index + 1) % TABLE_SIZE;
}
If index has already been used in hash table, we use the larger index. Now we can get the efficiency of this simple hash table:
Average Worst Case Space O(n) O(n) Search O(1) O(n) Insert O(1) O(n) Delete O(1) O(n)
Now if you pay enough attention, you will find out there is a flaw inside my simple hash table: I never handle hash-full situation. Basically, this hash table will enter a infinite loop in function findIndex() if the hash table is full. How do we handle that case?
We could fix that by using hash table chaining. Instead of having simple (key, value) pairs, we will have the value as
a linked list. If we are in a hash full situation, we just append it to the end of linked list.
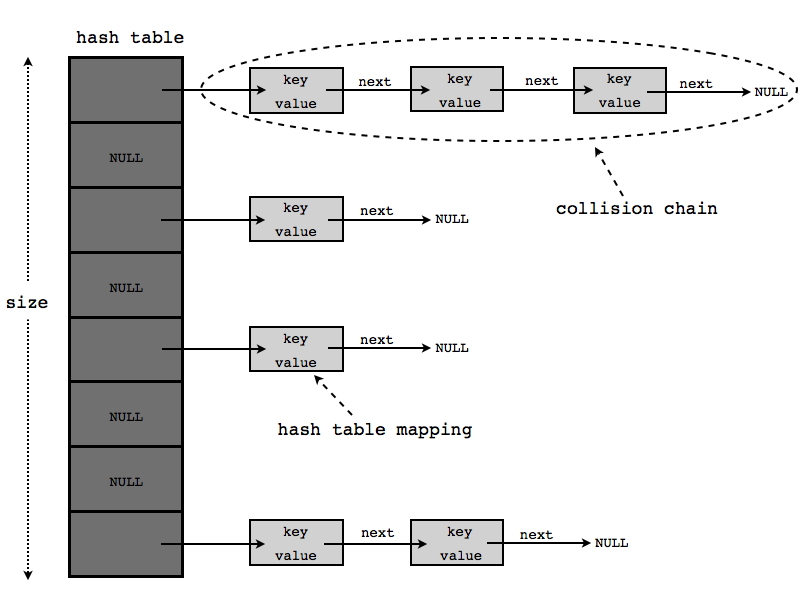
The code for hash table entry is:
public class LinkedHashEntry {
String key;
int value;
LinkedHashEntry next;
/* Constructor */
LinkedHashEntry(String key, int value)
{
this.key = key;
this.value = value;
this.next = null;
}
}
The code for hash table is:
public class NotSoSimpleHashTable {
private int TABLE_SIZE;
private int size;
private LinkedHashEntry[] table;
/* Constructor */
public NotSoSimpleHashTable(int ts) {
size = 0;
TABLE_SIZE = ts;
table = new LinkedHashEntry[TABLE_SIZE];
for (int i = 0; i < TABLE_SIZE; i++)
table[i] = null;
}
/* Function to get number of key-value pairs */
public int getSize() {
return size;
}
/* Function to clear hash table */
public void clean() {
for (int i = 0; i < TABLE_SIZE; i++)
table[i] = null;
size = 0;
}
/* Function to get value of a key */
public int get(String key) {
int hash = (calculateHashCode( key ) % TABLE_SIZE);
if (table[hash] == null)
return -1;
else {
LinkedHashEntry entry = table[hash];
while (entry != null && !entry.key.equals(key))
entry = entry.next;
if (entry == null)
return -1;
else
return entry.value;
}
}
/* Function to insert a key value pair */
public void insert(String key, int value) {
int hash = (calculateHashCode( key ) % TABLE_SIZE);
if (table[hash] == null)
table[hash] = new LinkedHashEntry(key, value);
else {
LinkedHashEntry entry = table[hash];
while (entry.next != null && !entry.key.equals(key))
entry = entry.next;
if (entry.key.equals(key))
entry.value = value;
else
entry.next = new LinkedHashEntry(key, value);
}
size++;
}
public void remove(String key) {
int hash = (calculateHashCode( key ) % TABLE_SIZE);
if (table[hash] != null) {
LinkedHashEntry prevEntry = null;
LinkedHashEntry entry = table[hash];
while (entry.next != null && !entry.key.equals(key)) {
prevEntry = entry;
entry = entry.next;
}
if (entry.key.equals(key)) {
if (prevEntry == null)
table[hash] = entry.next;
else
prevEntry.next = entry.next;
size--;
}
}
}
/* Function calculateHashCode which gives a hash value for a given string */
private int calculateHashCode(String key) {
int mod = key.hashCode() % TABLE_SIZE;
return mod < 0 ? mod + TABLE_SIZE : mod;
}
}
Improvements on Performance
Of course, like everything else, there’s always a price for this improvement. The performance may be affected now that we have to go through a linked list instead of getting a single value. Besides, if some specific linked list is getting too long, we will need a rebalance function to improve performance. Those will not be included in this article 😀
However, we could make some other improvement. We could use bit-masking instead of modulo.
private final int tableSize = Integer.highestOneBit(TABLE_SIZE) << 1; private final int tableMask = tableSize - 1;
Then we could get the remainder by key.hashCode() & tableMask instead of key.hashCode() % TABLE_SIZE.
Take the following as example:
decimal -> binary
12345 -> 0011000000111001
32 -> 0000000000100000
32 - 1 -> 0000000000011111
12345 & 31 -> 0000000000011001
25 -> 0000000000011001

